https://www.scaler.com/topics/operating-system/process-scheduling/
https://courses.engr.illinois.edu/cs423/sp2018/slides/13-linux-schedulers.pdf Linux History

Introduction to scheduler, and Linux scheduling strategy https://www.cnblogs.com/vamei/p/9364382.html
10,000-character long text, hammer it! Demystifying the Linux Process Scheduler https://www.eet-china.com/mp/a111242.html
Talk about scheduling - Linux O(1) https://cloud.tencent.com/developer/article/1077507 Introduction to Linux Kernel Scheduling Mechanism https://loda.hala01.com/2017/06/linux-kernel.html
--- #### Linux 2.4 kernel: SMP implemented in kernel mode - The use of multiple processors can speed up the processing speed of the kernel, and the scheduler has a complexity of O(n) - The kernel scheduler maintains two queues: runqueue and expired queue - Both queues are always in order - When a process runs out of time slice, it will be inserted into the expired queue - When the runqueue is empty, swap the runqueue with the expired queue 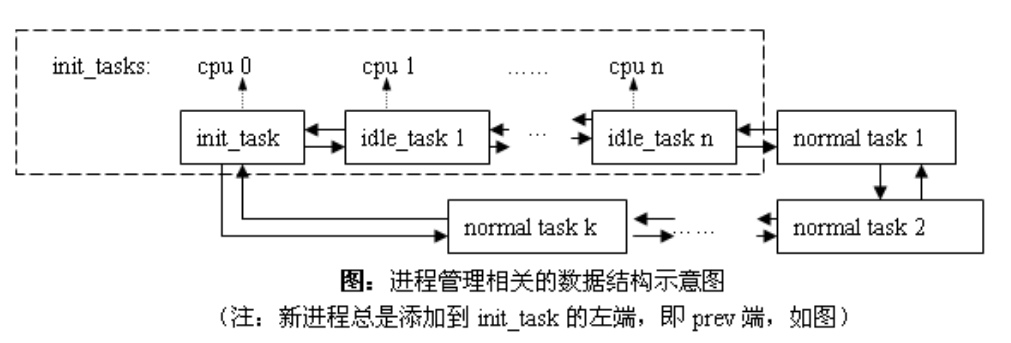 --- #### Linux 2.4 kernel: SMP implemented in kernel mode - The use of multiple processors can speed up the processing speed of the kernel, and the scheduler has a complexity of O(n) - Globally shared ready queue - Find the next executable process, this operation is usually O(1) - Every time a process runs out of time slices, find a suitable location to perform an insertion operation, and it will traverse all tasks with a complexity of O(n)  --- #### Linux 2.4 kernel: SMP implemented in kernel mode - The use of multiple processors can speed up the processing speed of the kernel, and the scheduler has a complexity of O(n) - Modern operating systems are capable of running thousands of processes - The O(n) algorithm means that every time you schedule, for the currently executed process, you need to go through all the processes in the expired queue and find a suitable place to insert - This will not only bring a huge loss in performance, but also make the scheduling time of the system very uncertain -- depending on the load of the system, there may be several times or even hundreds of times of difference 
10,000-character long text, hammer it! Demystifying the Linux Process Scheduler https://www.eet-china.com/mp/a111242.html
How does Linux schedule processes? https://jishuin.proginn.com/p/763bfbd2df25